


Über 50 % der Unternehmen haben laut einer Studie von BearingPoint bereits Projekte umgesetzt und über 75 % beschäftigen sich aktuell mit dem Thema. Gleichzeitig sagen fast alle Befragten, dass die Potenziale noch lange nicht ausgeschöpft sind.
Woran liegt es, dass die Potenziale noch nicht ausgeschöpft sind?
Die Frage ist, ob die Umsetzung die technologischen Möglichkeiten voll ausnutzt. Reine Dashboards basierend auf statistischen Modellen sind meist kein Gamechanger und revolutionieren die Arbeit des Unternehmens nicht komplett. Viel mehr sind sie die Basis dafür, mit intelligenten Modellen einen wirklichen Unterschied zu machen.
Dabei ist es zunächst wichtig zu verstehen, was sich Unternehmen von der Einführung von Predictive Maintenance-Systemen erwarten:
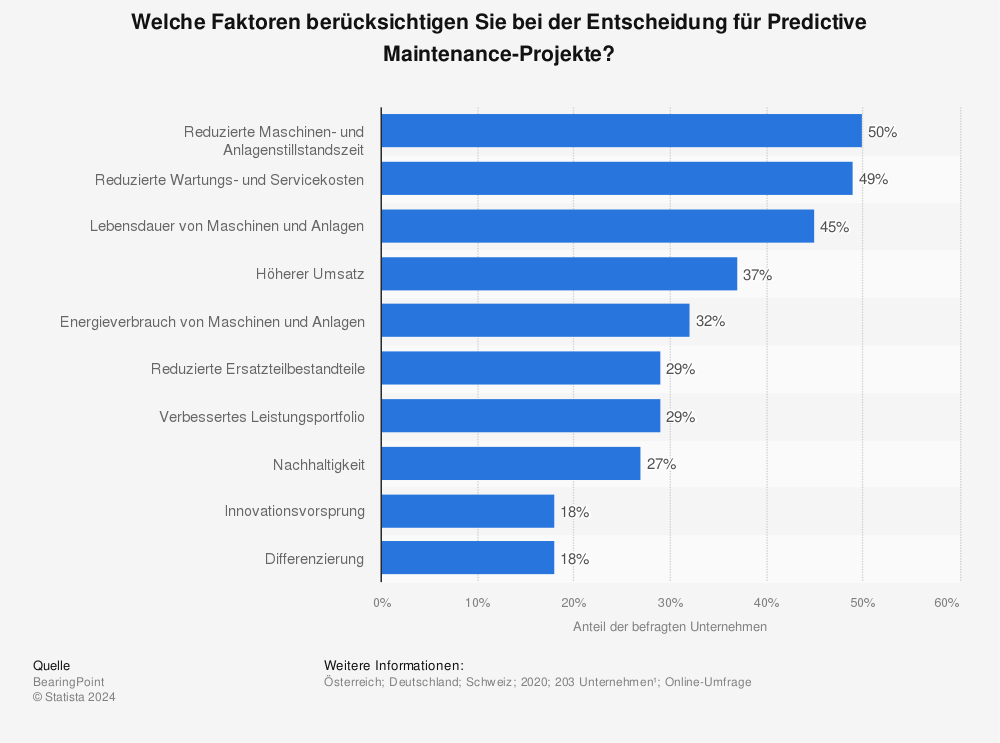
Die dominanten Kriterien für die Einführung von Predictive Maintenance-Systemen sind die Reduktion von Kosten (durch die Optimierung von Wartungskosten und die verlängerte Lebensdauer) sowie die Reduktion von Ausfallzeiten. Die entwickelten Modelle sollten also diese Kriterien im Fokus halten.
Statistische Verfahren als Grundlage
Die Grundlage eines jeden Predictive Maintenance-Systems sind Daten aus unterschiedlichsten Sensoren. Diese Daten sind im Allgemeinen schwierig zu beschaffen, so heterogen wie der Maschinenpark selbst und nicht standardisiert. Gleichzeitig ist die Frequenz der Datenaktualisierung oft unterschiedlich.
Der erste Schritt muss also zunächst die Harmonisierung dieser Daten sein. Oft spricht man bei der Repräsentation einer Maschine mit all ihren Datenpunkten vom Digitalen Zwilling der Maschine. Die unterschiedlichen Daten laufen an einem zentralen Punkt zusammen und werden für die Nutzung harmonisiert und in ein gemeinsames Schema gebracht.
Was die meisten Dashboards nun im ersten Schritt machen, ist die Visualisierung der erfassten Daten für eine Maschine als Funktion der Zeit darzustellen. Die Messwerte werden also in verschiedenen Diagrammen in einen zeitlichen Kontext gestellt und unterschiedlich kombiniert. Ziel ist es zunächst, Hinweise auf Anomalien zu entdecken und in der Zeit „davor“ Hinweise auf das Auftreten dieser Anomalien zu identifizieren, damit künftig frühzeitiger auf drohende Probleme reagiert werden kann.
Wenn es über die reinen Dashboards hinausgeht, werden meist Modelle zur Berechnung von statistischer Abweichung herangezogen. Für jeden Sensor-Wert können harte und weiche Thresholds für die Abweichung vom Optimalwert (Healthy State) festgelegt werden, aus denen dann Hinweise für Entscheidungen abgeleitet werden (können).
Sich wiederholende Muster können im besten Fall Hinweise auf notwendige Veränderungen der Thresholds bieten.
Probleme mit rein statistischen Modellen & Dashboards
Leider reichen die Systeme, die sich auf das Visualisieren und das Beobachten statistischer Abweichungen konzentrieren, in der Realität oft nicht aus:
Die Fehlerketten in Maschinen sind so komplex, dass sie nicht allein durch einen einzelnen Sensor und seine zeitlichen Werte dargestellt werden können. Oft ist es die Kombination aus einer Vielzahl von Sensordaten, die auf eine tatsächlich relevante Anomalie hinweisen. Ein Threshold auf einem einzelnen Sensor ohne Abhängigkeit zu anderen Werten kann sogar zu eher mehr Arbeit führen, weil Abweichungen, die auf Einzelsensorebene erfasst werden, zu Meldungen führen können, die gar keine realen Effekte haben.
Aus der schwierigen Visualisierung und Erkennung von Abhängigkeiten zwischen den einzelnen Sensoren in einzelnen Dashboards resultiert auch, dass die Visualisierung oft nicht für die Durchführung einer vollständigen Root Cause Analyse ausreicht. Die Abhängigkeiten zwischen den verschiedenen Sensoren können kaum bis gar nicht identifiziert werden.
Die Thresholds müssen häufig reevaluiert werden. Wenn sich Umgebungsparameter ändern, können gelernte historische Abhängigkeiten und Thresholds falsch sein und die bisher gültigen Regeln für Entscheidungen werden obsolet.
Die erlernten Regeln müssen für jede Maschine neu entwickelt werden. Jede kleine Veränderung sorgt dafür, dass kaum Generalisierung möglich ist. Da aber auch die Entwicklung der Modelle den Wartungskosten pro Maschine zugeordnet werden muss, so wird eines der wichtigsten Ziele, eben die Reduktion genau dieser Kosten, außer Acht gelassen bzw. sogar torpediert.
Verbesserungen durch den Einsatz von künstlicher Intelligenz
Dank der massiven Fortschritte im Bereich der künstlichen Intelligenz, vor allem aber dank der Verfügbarkeit einer Vielzahl von Werkzeugen, Methoden und Frameworks können unterschiedliche Formen von künstlicher Intelligenz als Ergänzung zu den bisherigen Werkzeugen genutzt werden. Natürlich basieren auch diese Werkzeuge grundsätzlich auf statistischen Modellen. Allerdings liefern sie dank ihrer „Intelligenz” bessere Möglichkeiten, die wirtschaftlichen Ziele aus der Datennutzung auch tatsächlich zu erreichen:
Durch Retraining kann auf veränderte Umweltbedingungen schnell reagiert werden. Die Thresholds verschieben sich automatisch regelmäßig und passen sich an die neuen Umgebungsvariablen an.
Während die klassischen Systeme versuchen, komplexe Zusammenhänge durch lineare Modelle abzubilden, bieten beispielsweise Deep Neural Networks die Möglichkeit, auch nicht lineare Modelle anzuwenden und so die Komplexität besser zu erfassen.
Dank der Nutzung von Ansätzen wie Vapnik–Chervonenkis Dimension Bounds bringt ein neu hinzugefügter Sensor kein Chaos ins System, sondern sorgt für eine Verbesserung der Genauigkeit der Datenerkennung.
Um die Root Cause-Analyse zu verbessern und zu automatisieren, kann zum Beispiel der Ansatz der SHAP Feature Importance herangezogen werden. Dabei wird vorhergesagt, wie sich die Veränderung eines Werts (Feature) auf die anderen Werte derselben Zeile (desselben Zeitpunkts) auswirkt. So kann jeder einzelne Sensorwert rückwirkend auf seine Auswirkung für die Anomalie bewertet werden. Die mögliche Vorhersage und damit die Abweichungserkennung wird damit viel genauer.
Wie künstliche Intelligenz einsetzen - Pareto vor Optimierung
Insbesondere für Unternehmen, die bereits erste Schritte in der Erfassung und Nutzung von Daten durch statistische Modelle unternommen haben, ist der Schritt zur Integration von Werkzeugen aus dem Bereich künstlicher Intelligenz keine große Herausforderung mehr. Verschiedene existierende Modelle können mit den vorhandenen Daten trainiert und so überprüft werden, ob ein spezielles Modell auf den bestehenden Daten die Chance hat, tatsächlich Mehrwerte zu generieren.
Für den flächendeckenden und skalierten Einsatz ist später eine Optimierung des Modells auf den eigenen Anwendungsfall wahrscheinlich notwendig. Dennoch können erste Mehrwerte schnell durch die Nutzung vortrainierter Modelle erreicht werden.
Der größte wirtschaftliche Nutzen entsteht dann, wenn die dank der künstlichen Intelligenz erkannten Frühindikatoren für Anomalien in (automatisierte) Entscheidungen einfließen und z.B. Einfluss auf Umgebungsvariablen nehmen, um der Anomalie entgegenzuwirken. So können die zuvor genannten wichtigsten kommerziellen Ziele für den Einsatz von Predictive Maintenance-Systemen auch tatsächlich erreicht werden.
Predictive Maintenance und künstliche Intelligenz bei mantro
Bei der Nutzung der erfassten Daten geht es neben der Nutzung für Predictive Maintenance aber auch um die Schaffung von technischen Grundlagen für die Etablierung von „as a Service”-Geschäftsmodellen. Bei dynamischen Teileproduktionsprozessen, insbesondere bei kleinen Losgrößen, ist es enorm wichtig, die Maschinen sehr genau zu kennen, um Rüstzeiten zu reduzieren und eine optimale Nutzung der Maschinen sicherzustellen. Wenn Maschinen- und Anlagenbauer auf neue Geschäftsmodelle abziehen, bei denen sie keine Einmalzahlung für eine Maschine mehr erhalten, sondern „as a Service” über ein wiederkehrendes, an die Nutzung der Maschine angepasstes Preismodell mit der Nutzung mitskalieren wollen, so haben sie ein hohes Interesse daran, jegliche Ausfallzeit zu verhindern und die Maschine maximal auszulasten.


